
15 Full State Feedback Controller
Hongbo Zhang
1) Overview of the Full State Feedback Controller

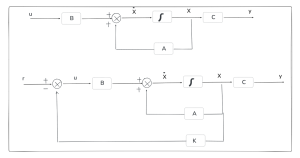
![x = [x_1; x_2; x_3]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-8a8a246666fda3a36afc9338b8820042_l3.png "Rendered by QuickLaTeX.com") . Similar to control block diagrams, flow diagrams show the relationships and interactions between the states, as in figures 15.2 and 15.3.
. Similar to control block diagrams, flow diagrams show the relationships and interactions between the states, as in figures 15.2 and 15.3.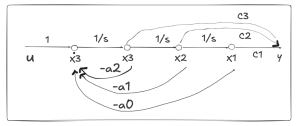
2) Controllability and Observability
Prior to the discussion of the system control and attempting to control the system, it is important to have a good understanding of the system controllability and observability. It would be counterproductive to spend significant effort to model the system and try to design a controller for it without first confirming the controllability and observability of the system.
2.1) System Controllability
![\[\dot{x}(t) = A x(t) + B u(t)\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f6295bfda59c1671fcb91b30687ac2a4_l3.png "Rendered by QuickLaTeX.com")
![\[ y(t) = Cx(t) + Du(t) \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-d7c54954f54a0871e3d86b36d0de3e6c_l3.png "Rendered by QuickLaTeX.com")
 is the system matrix,
is the system matrix,  is the input matrix,
is the input matrix,  is the output matrix, and
is the output matrix, and  is the feed-forward matrix. Based on the above state space definition, the controllability matrix
is the feed-forward matrix. Based on the above state space definition, the controllability matrix  is defined as:
is defined as: ![\[\mathcal{C} = [B \ AB \ A^2B \ \cdots \ A^{n-1}B]\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-0c09c56353bb1c2cd1d106dc9d7fec51_l3.png "Rendered by QuickLaTeX.com")
 is the number of states in the system. is nonzero
is the number of states in the system. is nonzero ![\[ |\mathcal{C}| \neq 0 \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-07a898cc8b2ac6f6cff89f7a043c624d_l3.png "Rendered by QuickLaTeX.com")
![\[\text{rank}(\mathcal{C}) = full rank\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-b66722bd3d24667931e6b28809d01e61_l3.png "Rendered by QuickLaTeX.com")
![\[A = \begin{pmatrix} 0 & 1 \\ -2 & -3 \end{pmatrix}, \quad B = \begin{pmatrix} 0 \\ 1 \end{pmatrix}\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-dee6d4a49162137fd91f8c126cbbab1f_l3.png "Rendered by QuickLaTeX.com")
To determine if this system is controllable, we need to construct the controllability matrix :
![\[\mathcal{C} = [B \ AB]\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-c8e124c7f802dbe331b1c51b638c7d37_l3.png "Rendered by QuickLaTeX.com")
First, we calculate  :
:
![\[AB = \begin{pmatrix} 0 & 1 \\ -2 & -3 \end{pmatrix} \begin{pmatrix} 0 \\ 1 \end{pmatrix} = \begin{pmatrix} 1 \\ -3 \end{pmatrix}\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-bc4919f634e81e9319b544213c4b138c_l3.png "Rendered by QuickLaTeX.com")
We know that the controllability matrix
Therefore, the controllability matrix C can be written as
![\[\mathcal{C} = \begin{pmatrix} 0 & 1 \\ 1 & -3 \end{pmatrix}\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-420e81356475455299b842a900a276a1_l3.png "Rendered by QuickLaTeX.com")
The determinate of the controllability matrix  = -1. The rank of the controllability matrix is two: full rank. So we can conclude that the system is controllable.
= -1. The rank of the controllability matrix is two: full rank. So we can conclude that the system is controllable.
![\[ A = \begin{pmatrix} 1 & 2 & 3 \\ 0 & -1 & 4 \\ 0 & 0 & -2 \end{pmatrix}, \quad B = \begin{pmatrix} 1 \\ 0 \\ 1 \end{pmatrix} \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-4e7d7467918f29fa15da24826aeef5a4_l3.png "Rendered by QuickLaTeX.com")
is: ![\[ \mathcal{C} = \begin{pmatrix} B & AB & A^2B \end{pmatrix} \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-dff50402cd133a87f687862a93a4274d_l3.png "Rendered by QuickLaTeX.com")
and  :
: ![\[ AB = \begin{pmatrix} 1 & 2 & 3 \\ 0 & -1 & 4 \\ 0 & 0 & -2 \end{pmatrix} \begin{pmatrix} 1 \\ 0 \\ 1 \end{pmatrix} = \begin{pmatrix} 4 \\ 4 \\ -2 \end{pmatrix} \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-855bd832f2d4cd0be99742ed60320e21_l3.png "Rendered by QuickLaTeX.com")
![\[ A^2B = A(AB) = \begin{pmatrix} 1 & 2 & 3 \\ 0 & -1 & 4 \\ 0 & 0 & -2 \end{pmatrix} \begin{pmatrix} 4 \\ 4 \\ -2 \end{pmatrix} = \begin{pmatrix} 0 \\ 12 \\ 4 \end{pmatrix} \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-e1a059eb27e52ed61de471597f2a685a_l3.png "Rendered by QuickLaTeX.com")
becomes: ![\[ \mathcal{C} = \begin{pmatrix} B & AB & A^2B \end{pmatrix} = \begin{pmatrix} 1 & 4 & 0 \\ 0 & 4 & 12 \\ 1 & -2 & 4 \end{pmatrix} \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-8206c40fa846c15700cfcf814ac48247_l3.png "Rendered by QuickLaTeX.com")
determinant becomes
![\[ \text{det}(\mathcal{C}) = 88 \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-d8675f39b33d43ff57204c0cdb424a47_l3.png "Rendered by QuickLaTeX.com")
becomes
![\[ \text{rank}(\mathcal{C}) = 3 \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-d7c83377bee8da50335b5a9ef1c78d28_l3.png "Rendered by QuickLaTeX.com")
2.2) System Observability
Similarly to controllability testing, observability testing is also begun from the system state space definition.
![\[ \dot{x}(t) = Ax(t) + Bu(t) \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-b421d5574245ff12f6e5ecb20ac10342_l3.png "Rendered by QuickLaTeX.com")
where is the system matrix, is the input matrix, is the output matrix, and is the feed-forward matrix.
Based on this definition, observability matrix  is defined as:
is defined as:
![\[ \mathcal{O} = \begin{pmatrix} C \\ CA \\ CA^2 \\ \vdots \\ CA^{n-1} \end{pmatrix} \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-fb3621d2660de9d8bb1a793f290f2420_l3.png "Rendered by QuickLaTeX.com")
where is the number of states.
Similar to the controllability matrix, the system is observable if the determinant of the observability matrix is nonzero:
![\[ |\mathcal{O}| \neq 0 \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-9a1d9103dbc30f5be1baab2cae759e6a_l3.png "Rendered by QuickLaTeX.com")
or the observability matrix rank is full rank.
![\[ \text{rank}(\mathcal{O}) = full rank \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-519a544105f69654198149ba1ebe2c22_l3.png "Rendered by QuickLaTeX.com")
Similarly, let us give some examples to better illustrate the observability check of the system.
Example 1:
Given A and B matrices as follows:
![\[A = \begin{pmatrix} 0 & 1 \\ -2 & -3 \end{pmatrix}, \quad C = \begin{pmatrix} 0 & 1\\ \end{pmatrix}\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-55b9fdd557126e22f3b1271566417728_l3.png "Rendered by QuickLaTeX.com")
The controllability matrix is given by:
![\[\mathcal{O} = \begin{bmatrix} C \\ CA \end{bmatrix}\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-dc9b502c04e364819c5231d8c5af7e2a_l3.png "Rendered by QuickLaTeX.com")
First, we compute  :
:
![\[CA = \begin{bmatrix} 0 & 1 \end{bmatrix} \begin{bmatrix} 0 & 1 \\ -2 & -3 \end{bmatrix} = \begin{bmatrix} -2 & -3 \end{bmatrix}\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-0f2df7dd7bb2d74d06a9bc2384defdaf_l3.png "Rendered by QuickLaTeX.com")
Therefore, the observability matrix is:
![\[\mathcal{O} = \begin{bmatrix} 0 & 1 \\ -2 & -3 \end{bmatrix}\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-242ff9de078330647437cdd362bab806_l3.png "Rendered by QuickLaTeX.com")
The determinant of the matrix C becomes
![\[ \text{det}(\mathcal{O}) = 2 \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-e4e935983fe37bd1876a55ceefac4162_l3.png "Rendered by QuickLaTeX.com")
As such, the system is observable.
Example 2:
Let us use the same 3×3 matrix as used in the controllability test to check the observability of the matrix.
![\[ A = \begin{pmatrix} 1 & 2 & 3 \\ 0 & -1 & 4 \\ 0 & 0 & -2 \end{pmatrix}, \quad B = \begin{pmatrix} 1 \\ 0 \\ 1 \end{pmatrix} ,\quad C = \begin{pmatrix} 1 & 0 & 1 \end{pmatrix} \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-01bd9989fbaff6ad44b50357c430e608_l3.png "Rendered by QuickLaTeX.com")
The observability matrix can be calculated through and  :
:
![\[ CA = \begin{pmatrix} 1 & 0 & 1 \end{pmatrix} \begin{pmatrix} 1 & 2 & 3 \\ 0 & -1 & 4 \\ 0 & 0 & -2 \end{pmatrix} = \begin{pmatrix} 1 & 2 & 1 \end{pmatrix} \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-af1757eda4c4a4a7cf466a275ba87317_l3.png "Rendered by QuickLaTeX.com")
![\[ CA^2 = C(A^2) = \begin{pmatrix} 1 & 0 & 1 \end{pmatrix} \begin{pmatrix} 1 & 2 & 3 \\ 0 & -1 & 4 \\ 0 & 0 & -2 \end{pmatrix} \begin{pmatrix} 1 & 2 & 3 \\ 0 & -1 & 4 \\ 0 & 0 & -2 \end{pmatrix}\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-a989835801b6aad015af49a48a32109d_l3.png "Rendered by QuickLaTeX.com")
![\[= \begin{pmatrix} 1 & 2 & 1 \end{pmatrix} \begin{pmatrix} 1 & 2 & 3 \\ 0 & -1 & 4 \\ 0 & 0 & -2 \end{pmatrix} = \begin{pmatrix} 1 & 2 & -5 \end{pmatrix} \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-44f2a42adb4b19768546c691bde27097_l3.png "Rendered by QuickLaTeX.com")
With , and , the observability matrix becomes:
![\[ \mathcal{O} = \begin{pmatrix} C \\ CA \\ CA^2 \end{pmatrix} = \begin{pmatrix} 1 & 0 & 1 \\ 1 & 2 & 1 \\ 1 & 2 & -5 \end{pmatrix} \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-be2f0f2c22a90747fe66535283ba7b92_l3.png "Rendered by QuickLaTeX.com")
The determinant of the 
![\[ \text{det}(\mathcal{O}) = -12 \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-a88b0fe592ff23d4678c7afda5a8b59c_l3.png "Rendered by QuickLaTeX.com")
The rank of the observability matrix is full rank 3. As such, the system is observable.
3) Full State Feedback Control
3.1 Principle of Full State Feedback Control
The full state feedback control involves coefficient matching between the desired characteristics equation and the feedback control system characteristics equation to solve the feedback control gain K. In contrast to the linear quadratic regulator (LQR) and model predictive controller (MPC), the full state feedback controller is simpler to use and often yields the desired control gain K using more straightforward computation.
There are three major steps involved in calculation of the control gain K. The first step involves the calculation of the desired characteristics equation. The desired characteristics equation can be calculated using the damping ratio and natural frequency, which in turn can be calculated from overshoot and settling time, as shown in the first step of full state feedback control below.
Step 1: It should be noted that the dimension of the state space and the order of the desired characteristics equation correspond. For the two-by-two state space matrix, the order of the desired characteristics equation is two (second order). For higher dimensions of the state space, the order of the desired characteristics equation will increase. For this situation, we need to add augmented poles (S1 and S2 shown in Figure 4) for the first step of full state feedback control.
These augmented poles will be calculated using the system poles, which are the roots of the second order desired characteristics equation. The plant’s second order desired characteristics equation is written as:
![\[s^2 + 2\zeta\omega_n s + \omega_n^2 = 0\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-48e1837519491b5f585f80c2a926da8d_l3.png "Rendered by QuickLaTeX.com")
Note that different values of  lead to different control system behaviors:
lead to different control system behaviors:
 : Undamped system (pure oscillation).
: Undamped system (pure oscillation).
 : Underdamped system (oscillatory response with decaying amplitude).
: Underdamped system (oscillatory response with decaying amplitude).
 : Critically damped system (fastest response without oscillation).
: Critically damped system (fastest response without oscillation).
 : Overdamped system (slow response without oscillation).
: Overdamped system (slow response without oscillation).
The selection of augmented poles can be based on heuristics rules. For example, the real components of the augmented poles S1 and S2 can be 5 times or even 10 times larger than the roots of the above desired plant second order characteristics equation. Frequently, a trial-and-error approach is used to finalize the choice of S1 and S2. Of course, for the even higher dimensional state space, such as a 5×5 state space matrix, we will need three augmented poles: S1, S2, and S3 (2nd order system of 2 plant poles + 3 augmented poles = 5 poles total). Similarly, for the 6×6 state space matrix, we will need four augmented poles, S1, S2, S3, and S4. Together with two plant control system poles, this will make six poles to satisfy the total number of poles needed for a 6×6 state space matrix.


Step 2: The second step involves the calculation of the control system characteristics equation. The control system characteristics equation is
![\[ det(SI-(A-BK)) \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-53b91d7d6faceabaca6ea346d4e5ea23_l3.png "Rendered by QuickLaTeX.com")
Where I is the identity matrix.
![\[ [K_1, K_2, K_3... K_n ] \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-cec8666b84cc6bbf8232b55e2d027f7b_l3.png "Rendered by QuickLaTeX.com")
Note that for phase variable form, the matrix A can be written as follows:
![\[ \mathcal{A} = \begin{pmatrix} 0 & 1 & ... & 0 \\ 0 & 0 & ... & 0 \\ -a_0 & -a_1 & ... & -a_{n-1} \\ \end{pmatrix} \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-cd04da226c9adfba367dc7a97a37393a_l3.png "Rendered by QuickLaTeX.com")
![\[ \mathcal{A-BK} = \begin{pmatrix} 0 & 1 & ... & 0 \\ 0 & 0 & ... & 0 \\ -(a_0+k_1) & -(a_1+k_2) & ... & -(a_{n-1}+k_n) \\ \end{pmatrix} \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-849e95c661d72bb3cef8a67fdb3c4dff_l3.png "Rendered by QuickLaTeX.com")
For this condition, the characteristics equation (also the determinant of (SI- (A-BK)) becomes:
![\[ det(SI-(A-BK)) = s^n + (a_{n-1} + k_n)s^{n-1}+ ... + (a_0+k_1)\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-49f77184bd915c7664ad5ad7e40e0d19_l3.png "Rendered by QuickLaTeX.com")
You can find two interesting behaviors for the determinant of the phase variable type state space SI – (A-BK). First, you can easily find that the value of the last row and last column of the A-BK matrix becomes the first coefficient of the determinant, whereas the value of the last row and first column becomes the last coefficient of the determinant. Second, it is also obvious that the sign of the coefficient is opposite as well between the last row of the A-BK matrix and the characteristic equation coefficients. However, this pattern only holds for the phase variable state space. Unfortunately, does not hold for other types of state space, such as control canonical and observer. For these, you must calculate the determinant in order to obtain the characteristic equation.

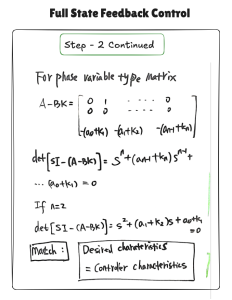
Step 3: Match Characteristic Equations to Solve K. Once the control system characteristics equation
is obtained, it is intuitive to match it with the desired control system characteristics equation to solve for the control gain K.
Control System Characteristics Equation = Desired Characteristics Equation

3.2 Case Study of the Full State Feedback Control
Given the system transfer function as follows, design a full state feedback controller to satisfy the following criteria: 15% overshoot, settling time of 0.5 seconds.
![\[ H(s) = \frac{20}{(s+2)(s+3)} \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-21e3ec6cf4cdd2d5905d58380730d5ab_l3.png "Rendered by QuickLaTeX.com")
Step 1: Let us calculate the desired characteristics equation. We know that the overshoot is 15%.
![\[ \%OS = 15\%\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-be458b520fe4d6692e2cb1b63f7e0af4_l3.png "Rendered by QuickLaTeX.com")
We also know the system equation
![\[ s^2 + 2\zeta\omega_n s + \omega_n^2 = 0\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-fb7e1afe03638a62636bf9f6fd4358f8_l3.png "Rendered by QuickLaTeX.com")
From which, we can derive the system damping ratio equation:
![\[\zeta = \frac{ln(\%OS/100)}{\sqrt{\pi^2 + ln(\%OS/100)^2}} \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-12c0922e6a87b6b1afd3de9672cbaf4d_l3.png "Rendered by QuickLaTeX.com")
![\[\zeta = 0.52 \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-fad51877ec60c8df851baff2e728fdb0_l3.png "Rendered by QuickLaTeX.com")
Similarly, we can also obtain the natural frequency equation
![\[ \omega_n = \frac{4}{T_s \zeta } \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-b56efa783a87dffa9f659d62d7aef896_l3.png "Rendered by QuickLaTeX.com")
Where  is the settling time.
is the settling time.
![\[\omega_n = 15.47 \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-bb951012cbd794b4b3ec71ecd349dc1a_l3.png "Rendered by QuickLaTeX.com")
As such, the desired characteristic equation becomes:
Where
![\[ \zeta = 0.52, \omega_n = 15.47 \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-da598dddab9142276e3c75d2ed8bb7af_l3.png "Rendered by QuickLaTeX.com")
It thus becomes:
![\[ s^2 + 16 s + 239.5 = 0\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-5c2578961f6ea897df4c57d93afe3c35_l3.png "Rendered by QuickLaTeX.com")
Step 2: Based on this transfer function, we can also obtain the following state space (matrices A and B are the same as in Example 1, above).
![\[A = \begin{bmatrix} -3 & 1 \\ 0 & -2 \end{bmatrix}\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-82d21089d6b42c13d42c05df14fa1e85_l3.png "Rendered by QuickLaTeX.com")
![\[B = \begin{bmatrix} 0 \\ 1 \end{bmatrix}\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-ba7918718ec34aaf08cb523d0c29af24_l3.png "Rendered by QuickLaTeX.com")
![\[C = \begin{bmatrix} 20 & 0 \end{bmatrix}\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-6ce5ad6b574b14755bdaade4d202e45d_l3.png "Rendered by QuickLaTeX.com")
![\[D = \begin{bmatrix} 0 \end{bmatrix}\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-e40f9cce348297411d9072adcafb5ee0_l3.png "Rendered by QuickLaTeX.com")
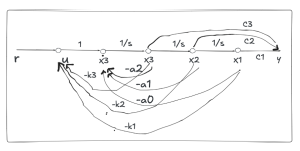
With the state space, we can easily draw the feedback flow diagram as shown below. With the flow diagram, we can find that there are two feedback gains K1 and K2. It is evident that all states (X1 and X2) of the flow diagram are associated with feedback gains (K1 and K2). As such, we call it full state feedback. The feedback flow diagram of the cascade type flow diagram is shown in Figure 15.9.
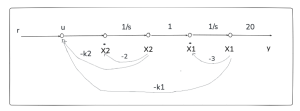
For the above flow diagram, the state space with feedback term is shown below. Note that only the A matrix has the feedback term; B, C, and D matrices do not have the feedback term.
![\[A - BK = \begin{bmatrix} -3 & 1 \\ -k_1 & -k_2-2 \end{bmatrix}\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-6af6e3e8b8449ead085196aabd6eec6f_l3.png "Rendered by QuickLaTeX.com")
![\[\begin{bmatrix} \dot{x_1} \\ \dot{x_2} \end{bmatrix} = \begin{bmatrix} -3 & 1 \\ -k_1 & -k_2-2 \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} + \begin{bmatrix} 0 \\ 1 \end{bmatrix}r\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f11bc7c55a2ae2c598184123c293d9da_l3.png "Rendered by QuickLaTeX.com")
![\[Y = \begin{bmatrix} 20 & 0 \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \end{bmatrix}\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-e40449102104ca7ebdaacf0c0d121329_l3.png "Rendered by QuickLaTeX.com")
With the above feedback state space, we can obtain the following characteristics equation.
![\[ det(SI-(A-BK)) = det\begin{bmatrix} \begin{bmatrix} s & 0\\ 0 & s \end{bmatrix} - \begin{bmatrix} -3 & 1 \\ -k_1 & -k_2-2 \end{bmatrix} \end{bmatrix} = det\begin{bmatrix} s+3 & -1 \\ k_1 & s+k_2+2 \end{bmatrix} \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-e7cd0dac9da149e2b36ce9f6dbf13ced_l3.png "Rendered by QuickLaTeX.com")
![\[ = (s+3)(s+k_2+2) +k_1 \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-e4300cfc6d8b0c4d2e48a2a4c1a163d7_l3.png "Rendered by QuickLaTeX.com")
![\[ = s^2 + (k_2+5)s + 3k_2 + 6 + k_1 \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-1183f90b4204f7718c64bb17d94ef126_l3.png "Rendered by QuickLaTeX.com")
Step 3: We know the desired characteristic equation is:
The system characteristic equation is:
![\[ 0 = s^2 + (k_2+5)s + 3k_2 + 6 + k_1 \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-16b5ea1cfd7ec575bf8f43a87601b4cc_l3.png "Rendered by QuickLaTeX.com")
We therefore need to match coefficients between the two equations to solve K1 and K2. In doing so, we can obtain the following two equations to solve K1 and K2.
![\[ k_2+ 5 = 16\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-605bff53be67e789630ff2d02b6575d6_l3.png "Rendered by QuickLaTeX.com")
![\[3k_2 + 6 + k_1 = 239.5 \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-168ae8cf65e0f602ff497e5aec5f0241_l3.png "Rendered by QuickLaTeX.com")
Therefore, we can obtain
![\[k_1 = 233.5\]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-8ecd574a21dfb8196ebaaf7798e67f9c_l3.png "Rendered by QuickLaTeX.com")
![\[ k_2 = 11 \]](https://mtsu.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-f61ba80513cb167559c23e694b61abc4_l3.png "Rendered by QuickLaTeX.com")
